Kubernetes 核心組件介紹
tags: Kubernetes
category: DevOps
description: Kubernetes 核心組件介紹
created_at: 2026/01/19 18:00:00
事前準備
- 有一個
Kubernetes環境,讓你可以做這一篇的實驗 沒有的話也沒關係,純看就好
前言
雖然可能順序有點怪,前面環境都裝好了,這一篇才來介紹核心組件,但我覺得在什麼都沒有的情況下,光講這些組件和概念會很乾很抽象,所以決定先把環境弄好(在最後嘗試建立一個簡單的 nginx 和 expose 服務),然後再來介紹核心組件。
有些東西可能還沒說明到,但可以就先看過去,之後的文章會再慢慢補齊。
目錄
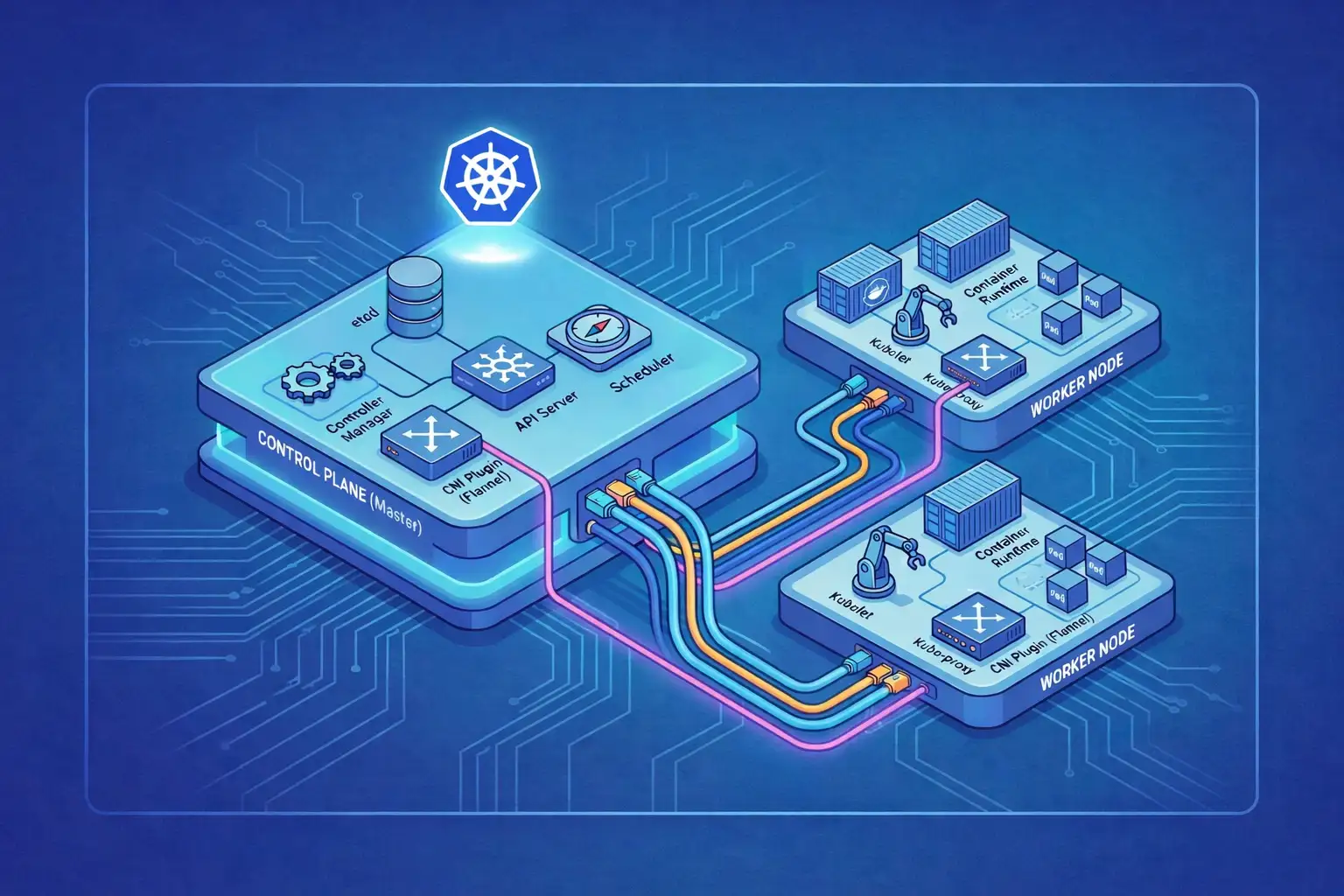
官方的架構圖
 圖片來源: Kubernetes 官方文件 - Cluster Architecture
圖片來源: Kubernetes 官方文件 - Cluster Architecture
我們可以從上圖注意到有幾個重要的組件:
Control Planekube-api-servercontroller-managercloud-controller-manageretcdscheduler
Nodekubeletkube-proxyCRI(Container Runtime Interface)Pod
另外如果有使用 CNI(Container Network Interface) 的話,還會有網路插件(Network Plugin)的部分,我們這邊使用的是 Flannel。
然後雖然上面的圖沒有將 master node 的 kubelet、kube-proxy、CRI、Pod 畫出來,但實際上這些組件也是會在 master node 上執行的。
接下來會針對這些組件做介紹。
節點介紹
Control Plane
Control Plane 是 k8s 的控制平面,負責管理整個叢集的狀態和運作,也就是我們平常所說的 Master Node。
這個節點上會執行多個組件,這些組件不一定要在同一個節點上跑,之後的文章除了特別需要實驗高可用以外,其餘部分為了簡化,我們都會把這些組件都放在同一個節點上。
沒意外的話最後應該會有一篇是介紹如何設定高可用的 k8s 叢集,然後去做一下實驗。
Node
Node 是 k8s 叢集中的工作節點(worker node),負責執行應用程式和服務。 每個節點都包含了多個組件,這些組件負責管理和執行 Pod。
各組件介紹
kubelet
kubelet 是執行在每個節點上的代理程式,負責監控和管理該節點上的 Pod,它會定期向 kube-api-server 報告節點與 Pod 的健康狀態,並根據 kube-api-server 上的資料變動,來執行 Pod 的啟動、停止或重啟。
另外如果是 static pod 的話,會有一點點不太一樣,細節可以看後面 kube-api-server 的部分。
kube-proxy
kube-proxy 是執行在每個節點上的網路代理程式,負責管理節點上的網路流量。 它會根據服務的定義來設定網路規則,確保流量可以正確地導向到對應的 Pod。
如果有使用 CNI 的話,CNI 可能會取代 kube-proxy 的部分或全部功能(也可能不會),這取決於所使用的 CNI 插件。
若是純粹使用 kube-proxy 的話,kube-proxy 會使用 iptables(預設) 或 IPVS 來設定網路規則,這些規則會根據服務的定義來決定如何將流量導向到對應的 Pod。
例如像是假設你建立一個 deployment,然後設定有三個副本(replica),接著再建立一個 service 來暴露這個 deployment,這時候 kube-proxy 會設定三條規則,分別將流量導向到這三個 pod,在看 iptables 的 nat 表前,我們先看一下建立出來的資源:
# pod
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6ff797d4c9-7z47r 1/1 Running 0 5m 10.244.1.5 k8s-worker-1 <none> <none>
nginx-deployment-6ff797d4c9-s9xfp 1/1 Running 0 5m 10.244.2.3 k8s-worker-2 <none> <none>
nginx-deployment-6ff797d4c9-sd6vq 1/1 Running 0 5m 10.244.1.4 k8s-worker-1 <none> <none>
# service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-deployment NodePort 10.108.237.183 <none> 8080:31001/TCP 5m接著看一下 nat 表的規則:
> sudo iptables -t nat --list
Chain KUBE-SVC-WRNOD73BKRQH4VVX (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !k8s-master/16 10.108.237.183 /* default/nginx-deployment cluster IP */ tcp dpt:http-alt
KUBE-SEP-2QL67MPZQIZMKP54 all -- anywhere anywhere /* default/nginx-deployment -> 10.244.1.4:80 */ statistic mode random probability 0.33333333349
KUBE-SEP-MFS7EKMTHUB5I4J7 all -- anywhere anywhere /* default/nginx-deployment -> 10.244.1.5:80 */ statistic mode random probability 0.50000000000
KUBE-SEP-5WALNC42XGEBI4PK all -- anywhere anywhere /* default/nginx-deployment -> 10.244.2.3:80 */第一條 KUBE-MARK-MASQ 是用來標記這個流量需要做 masquerade 的,但這邊先不細究,後面三條則是將流量導向到三個不同的 pod。
如果從 nat 表的前面開始看起的話,大概會過到這一些規則:
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-SVC-ERIFXISQEP7F7OF4 tcp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns-tcp cluster IP */ tcp dpt:domain
KUBE-SVC-JD5MR3NA4I4DYORP tcp -- anywhere 10.96.0.10 /* kube-system/kube-dns:metrics cluster IP */ tcp dpt:9153
KUBE-SVC-NPX46M4PTMTKRN6Y tcp -- anywhere 10.96.0.1 /* default/kubernetes:https cluster IP */ tcp dpt:https
KUBE-SVC-WRNOD73BKRQH4VVX tcp -- anywhere 10.108.237.183 /* default/nginx-deployment cluster IP */ tcp dpt:http-alt
KUBE-SVC-TCOU7JCQXEZGVUNU udp -- anywhere 10.96.0.10 /* kube-system/kube-dns:dns cluster IP */ udp dpt:domain
KUBE-NODEPORTS all -- anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL可以看到,一開始流量會先進到 PREROUTING,然後被導向到 KUBE-SERVICES,接著再根據目的地 IP 位址被導向到對應的目標,例如這邊的 nginx-deployment 服務就會被導向到 KUBE-SVC-WRNOD73BKRQH4VVX,然後再根據規則將流量隨機導向到三個不同的 pod。
如果想要實驗的話,我們可以看一下 kube-proxy 是怎麼被建立的:
kubectl describe pod kube-proxy -n kube-system可以看到 Controlled By: DaemonSet/kube-proxy,這表示 kube-proxy 是由一個 DaemonSet 所管理的。
我們可以先把 daemonset 列出來看一下:
kubectl get daemonset -n kube-system你會看到像是這樣的輸出:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 3 3 3 3 3 kubernetes.io/os=linux 5d7h他的 DESIRED、CURRENT、READY 都是 3,這表示目前有三個節點在執行 kube-proxy,而且這三個 kube-proxy 都是健康的,然後他只會被部署在存在 kubernetes.io/os=linux 標籤的節點上。
那如果我希望他暫時不要部署,因為我想模擬沒有 kube-proxy 的情況下會發生什麼事,有個很暴力的作法(實驗用),我們把它的 node selector 加入一個不存在的標籤:
kubectl patch daemonset kube-proxy -n kube-system -p '{"spec":{"template":{"spec":{"nodeSelector":{"stopped":"true"}}}}}'接著你再去看一次 daemonset:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kube-proxy 0 0 0 0 0 kubernetes.io/os=linux,stopped=true 5d8h然後也看一下 pod:
kubectl get pods -n kube-system你會發現已經沒有任何的 kube-proxy 了。
然後這時我們再去對 service 做一些操作,你會發現 iptables 並不會被更新,因為 kube-proxy 已經不在了。
如果你是在 kube-proxy 不見之前就已經有 service 的話,這些規則還是會存在(所以會通),但如果你在沒有 kube-proxy 的情況下建立新的 service 的話,這些規則就不會被建立(所以不會通)。
所以也間接證明這些 pod 的流量不會經過 kube-proxy 這個 process,而是會直接被 kube-proxy 設定的 iptables 或 IPVS 規則所處理。
最後,當你實驗完成後記得把 kube-proxy 恢復回來:
kubectl patch daemonset kube-proxy -n kube-system --type json -p='[{"op": "remove", "path": "/spec/template/spec/nodeSelector/stopped"}]'CRI(Container Runtime Interface)
CRI 是一個標準化的介面,允許 k8s 與不同的 container runtime 進行互動。 常見的 container runtime 包括 Docker、containerd 和 CRI-O。
這麼做的目的是為了讓 k8s 可以支援多種不同的 container runtime,而不需要針對每一種 runtime 都寫一套專屬的程式碼。
就像我們開發的時候會使用 interface 來解耦不同的實作方式一樣,k8s 透過 CRI 這個介面來和不同的 container runtime 進行互動,這樣就可以讓 k8s 更加靈活和可擴展。
Pod
Pod 是 k8s 中最小的部署單位,代表一個或多個容器的集合(通常是一個),這些容器共享網路和存儲資源。 每個 Pod 都有一個唯一的 IP,並且可以包含多個容器,這些容器在 Pod 內部可以透過 localhost 進行通訊。
kube-api-server
kube-api-server 是 k8s 的核心組件,負責處理所有的 API 請求,並且維護叢集狀態(寫入/讀取 etcd)。它提供了一個 REST API,讓使用者和其他組件可以透過 HTTP 請求來與 k8s 叢集進行互動,也是整個 k8s 叢集唯一的入口。
也是這些核心組件當中唯一一個和 etcd 有直接互動的組件,其他組件都是透過 kube-api-server 來存取 etcd 的資料。
另外,kubectl 這個指令工具也是透過 kube-api-server 來和 k8s 叢集進行互動的。
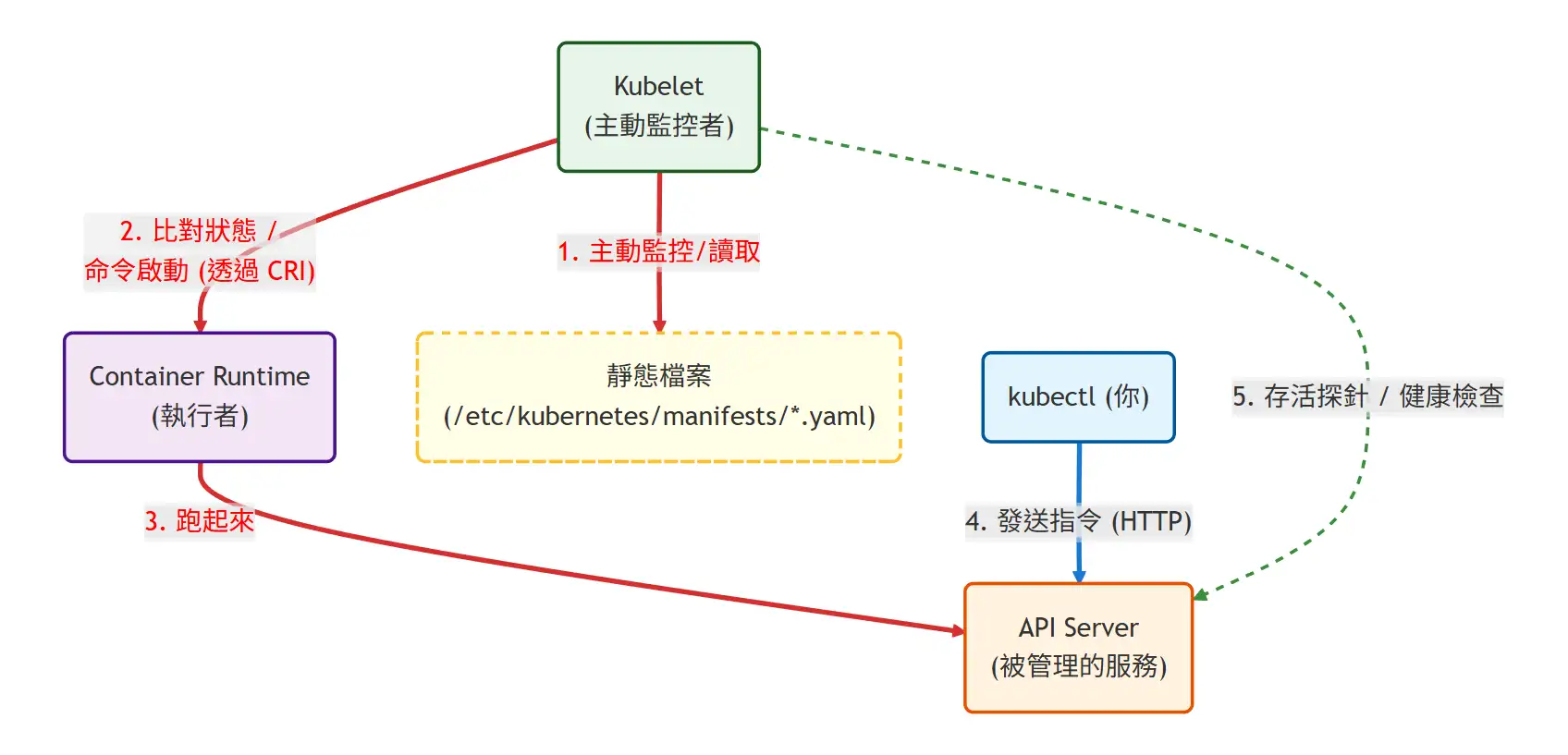
最後順便可以提一下,這個組件是由 kubelet 啟動的,並且以 static pod 的方式跑在 Control Plane 節點上。
如果你在你的 master node 上執行 kubectl get pods -A 的話,你會看到 kube-system 命名空間下有一個 kube-apiserver-<node-name> 的 Pod。
然後可以去 describe 這個 pod,你會看到 Controlled By: Node/k8s-master,這表示這個 pod 是屬於 static pod。
然後我們可以看一下 kubelet 是如何啟動 kube-api-server 的,還記得我們在第一篇安裝的時候有提到他的設定檔的位置:
KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml打開這個檔案,我們可以看到 kubelet 的設定,有包含一個 staticPodPath 的設定:
staticPodPath: /etc/kubernetes/manifests這表示 kubelet 會去這個路徑下尋找 static pod 的定義檔案,然後啟動這些 pod。
可以嘗試把這個目錄的檔案列出來,你會看到 kube-apiserver.yaml、kube-controller-manager.yaml、kube-scheduler.yaml、etcd.yaml 這些檔案,這些就是 Control Plane 的組件定義檔案。
你的節點會去監控這些 Pod 的狀態,當這些 Pod 不見了或者是失效了,kubelet 會自動重新建立這些 Pod。
我們可以嘗試在 host 把 kube-apiserver 的 process 給殺掉,然後過一會兒再去看 kubectl get pods -A,你會發現 kube-api-server 的 Pod 又回來了。
做這個實驗,我們先看一下 kube-apiserver 的 process:
ps aux | grep kube-apiserver接著你可以看他是哪個 pid,然後執行 sudo kill -9 <pid> 把他殺掉,或者是用下面這一段指令來直接殺掉:
sudo pkill -f kube-apiserver殺掉之後你可以立刻去看一下 ps aux | grep kube-apiserver,你會發現 kube-apiserver 的 process 已經不見了。
之後手快一些,去嘗試執行 kubectl get pods 之類的等等操作,你會發現會出現連線錯誤,因為 kube-api-server 不見了,他連不到 kube-api-server。
然後等個一小陣子, kubelet 會偵測到 kube-apiserver 不見了,然後重新啟動他,這時候你再去看 ps aux | grep kube-apiserver,你會發現 kube-apiserver 又回來了。
有點像是下面這張圖的關係:
controller-manager
controller-manager 是負責管理各種控制器的組件,這些控制器負責監控叢集的狀態,並且根據預定的規則來調整叢集的狀態,例如:
- 節點控制器(
Node Controller): 負責定期監控節點的狀態,當節點失效時,會將node標記一些狀態,而之後有新的pod需要調度時,自然就不會再調度到這些失效的節點上。 - 守護進程控制器(
DaemonSet Controller): 負責確保每個指定的節點上都執行指定的Pod,通常用於執行系統級別的服務,例如kube-proxy。 ...
但是所有的 controller 太多了,統一由這個 controller-manager 來管理和執行(aggregated),所以我們可以把他想像成一個 process 裡面跑了很多個 controller,也可以透過 kubectl logs 來查看這個組件的日誌,來看看他到底啟動了哪些 controller。
這些 controller 各司其職,確保叢集的狀態符合使用者的期望。
cloud-controller-manager
cloud-controller-manager 是用來和雲端服務提供商整合的組件,但因為我們這邊是使用本地的虛擬機器,所以這個組件並沒有實際作用。
如果之後有餘力去嘗試使用雲端服務的話,在一併介紹這個組件。
etcd
etcd 是一個分散式的鍵值存儲系統,負責存儲 k8s 叢集的所有狀態資訊,包括節點、Pod、服務等。 它提供了一個可靠的存儲機制,確保叢集的狀態可以在不同的組件之間一致地共享。
也就是如果今天要做備份 k8s 叢集的狀態資訊,通常就是備份 etcd 的資料。
scheduler
scheduler 是負責將 Pod 調度到適當的節點上的組件。 它會根據節點的資源狀態、Pod 的需求以及其他預定的規則來決定將 Pod 調度到哪個節點上。
kubectl
kubectl 是 k8s 的命令行工具,允許使用者與 k8s 叢集進行互動。 它提供了一個簡單的介面,讓使用者可以透過命令來管理叢集中的資源,例如建立、更新、刪除 Pod、服務等。
CNI(Container Network Interface)
CNI 是一個標準化的介面,允許 k8s 與不同的網路插件進行互動。 常見的網路插件包括 Flannel、Calico 等。
Flannel
Flannel 是一個簡單且易於使用的 CNI 插件,負責為 k8s 叢集中的每個節點分配一個虛擬網路,並且確保這些節點之間可以互相通訊。 它預設使用 VXLAN 技術來實現跨主機的網路連接,確保 Pod 可以在不同的節點之間進行通訊。
他實際上也是一個 DaemonSet,會在每個節點上啟動一個 flannel 的 pod,來管理該節點的網路設定。
當你裝好 flannel 之後,可以在每個節點上查看到一個名為 flannel.1 的虛擬網路介面以及一個 cni0 的橋接介面。
然後你的節點的路由表也會被更新,讓流量可以正確地導向到對應的 Pod,例如 route -n: (假設我們 pod CIDR 是 10.244.0.0/16)
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 10.0.2.2 0.0.0.0 UG 100 0 0 enp0s3
10.0.2.0 0.0.0.0 255.255.255.0 U 100 0 0 enp0s3
10.0.2.2 0.0.0.0 255.255.255.255 UH 100 0 0 enp0s3
10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
10.244.1.0 10.244.1.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.2.0 10.244.2.0 255.255.255.0 UG 0 0 0 flannel.1
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s8
192.168.1.1 10.0.2.2 255.255.255.255 UGH 100 0 0 enp0s3運作流程大概是這樣的:
【 Node A (寄件人) 】 【 Node B (收件人) 】
IP: 192.168.1.10 IP: 192.168.1.20
+--------------------------+ +--------------------------+
| Pod A (發送端) | | Pod B (接收端) |
| IP: 10.244.1.5 | | IP: 10.244.2.5 |
+------------|-------------+ +------------^-------------+
| 1. 原始小封包 | 7. 收到原始封包
v |
[ cni0 網橋 ] [ cni0 網橋 ]
| 2. 轉送(查路由表後) ^
v |
+--------------------------+ +--------------------------+
| flannel.1 | | flannel.1 |
| 3. 【加上資訊】(封裝) | | 6. 【解開資訊】(解封裝) |
| 📦 加上 VXLAN 頭 | | ✂️ 移除 VXLAN 頭 |
| 📦 加上 UDP / 外層 IP | | 🗑️ 丟掉外層包裝 |
+------------|-------------+ +------------^-------------+
| 4. 變成大包裹 | 5. 收到大包裹
v |
[ eth0 實體網卡 ] =========================== [ eth0 實體網卡 ]
實體網路傳輸 (隧道)By Gemini 繪製XD
小結
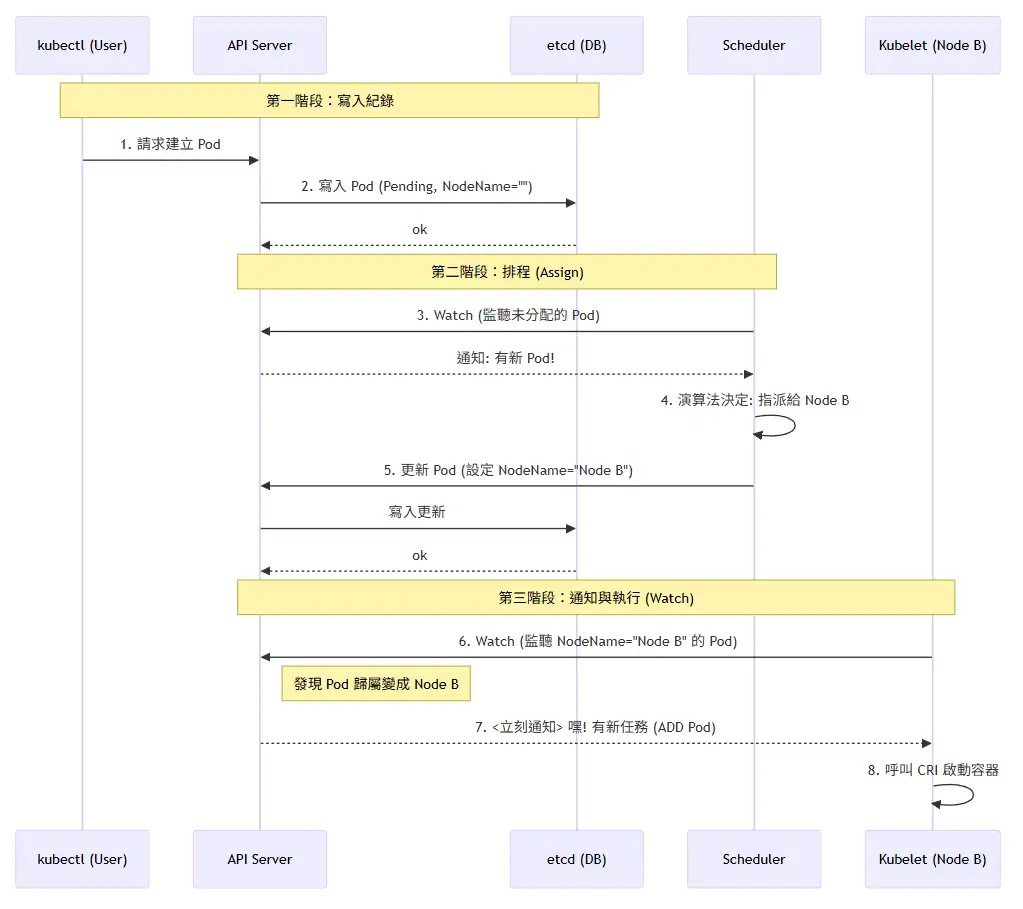
我們來總結一下這些核心組件是如何一起運作的:
kubelet、controller-manager、scheduler都會去監聽(watch)kube-api-server上的資料變動。- 使用者透過
kubectl發送一個建立Pod的請求到kube-api-server。 kube-api-server接收到請求後,會將Pod的定義存儲到etcd中。scheduler發現有新的Pod被建立時,會根據節點的資源狀態和Pod的需求來決定將Pod調度到哪個節點上,然後向kube-api-server發送更新請求,將Pod的調度結果存儲到etcd中。kubelet發現有新的Pod需要被啟動,且node就是當前機器時,根據kube-api-server上的資料變動,來啟動對應的Pod。controller-manager持續監控叢集的狀態,確保叢集的狀態符合使用者的期望,並且根據預定的規則來調整叢集的狀態。- 使用者透過
kubectl發送其他的請求來管理叢集,例如更新Pod、刪除Pod等,這些請求都會經過kube-api-server,然後由其他組件來處理。
其中第三步到第五步是持續進行的,他們沒有順序性。
可以參考下面這一張圖來理解這些組件之間的互動關係: