
Paper Crawler (download pdf)
created_at: 2024/11/12 23:30:00
一個微服務架構實作的論文爬蟲系統,這個系統每個服務都可以單獨運作、部署,方便擴充支援的網站。
為什麼會有這個服務
...有人有需求,於是我想了想,這樣可以解決問題,然後我想說當練手,於是這個服務就誕生了。
Demo
大概說明一下:
- 一開始要輸入一串預先產好的
token做最最基本的防禦(因為畢竟還是有public到網路上,雖然沒有給其他人) - 爬取過程有機會失敗,若失敗會有相應的錯誤訊息(
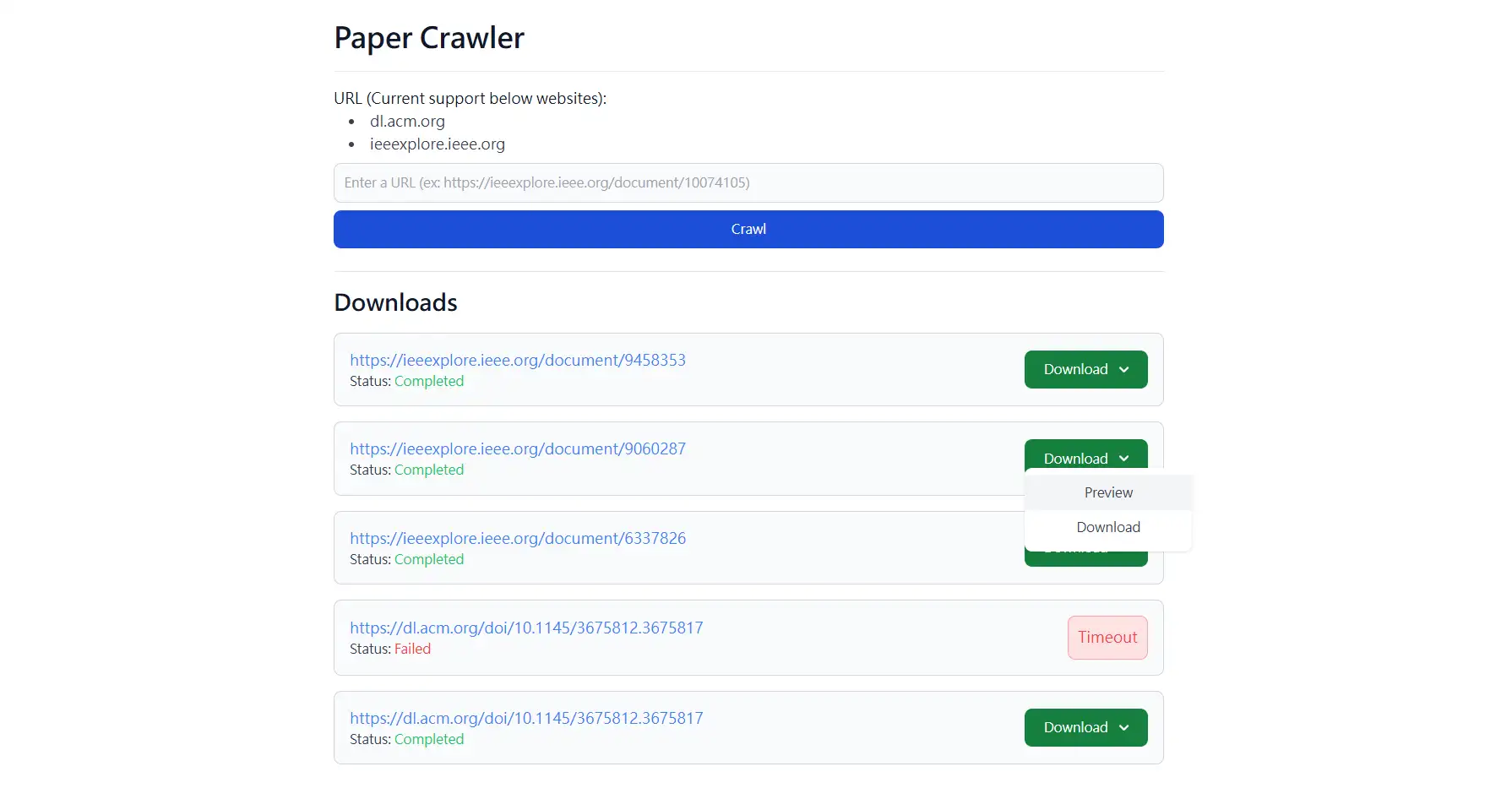
timeout、something went wrong等等),若是something went wrong的話,有可能的問題很多,所以要看一下log才能知道是什麼問題,但不方便透露給前端,所以就只有something went wrong這樣的訊息,但失敗不影響服務的運作 - 爬取成功後,可以預覽或是下載
PDF檔案- 預覽是打開新分頁(
blob)顯示PDF檔案 - 下載是直接下載
PDF檔案(檔名會正確) - 註1
- 預覽是打開新分頁(
- 使用者重新整理頁面會保留當前的狀態,但如果使用者整個
session都關掉,就會回到最初的狀態- 這邊使用者定義為同一個
real ip
- 這邊使用者定義為同一個
註1: 為什麼不預覽然後讓使用者直接 Ctrl + S 呢? 為什麼還要多做一個下載的按鈕?
簡短來說是為了提高下載的 UX,細節的話主要是因為我的檔案也有受到 token 的保護,所以除非我在後端特別做一些比較麻煩的處理,不然如果透過單純預覽的方式下載,檔名會是 blob,這樣對於使用者下載的 UX 來說不太好,所以額外提供一個下載的按鈕,就可以透過 Content-Disposition 來取得正確的檔名。
- 其實有兩個下載的按鈕,下拉選單本身也是
Source code 目前沒辦法公開,有兩個原因:
- 我還沒整理好
code 畢竟是這種服務,公開讓大家去爬蟲的話,好像不太好(雖然需要帳號)
但我可以放上架構和一些實作流程(?)
Tech Stack
Frontend:Svelte 5、Tailwind CSS、EventSourceBackend:Gin、gRPC、Python、RabbitMQCI/CD:Github Actions
沒有資料庫,因為並不打算做資料的儲存,重啟服務後又和乾淨的一樣。
宏觀的系統架構
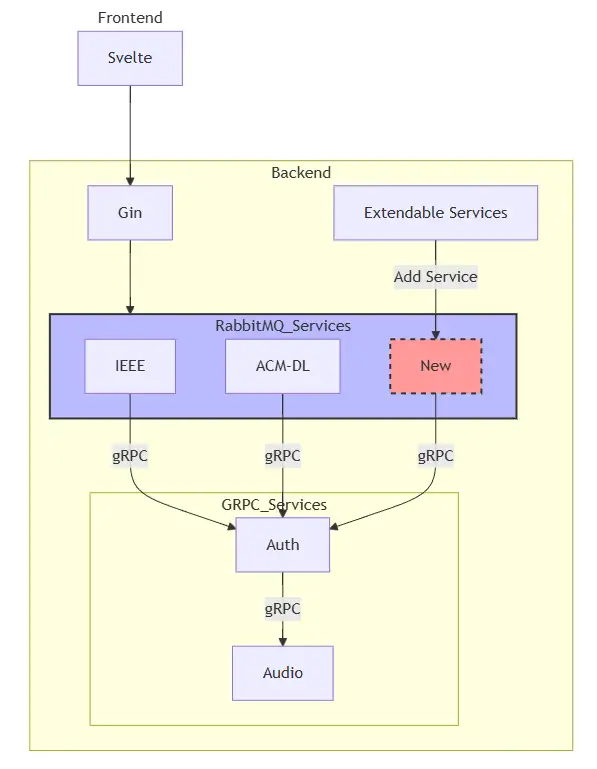
這個架構圖省掉了一些細節,主要是呈現可以輕易的擴充服務的部分。
另外 Auth 的部分其實可以與 Audio 服務整合成一個服務,因為在這個系統中並沒有其他服務去使用 Audio(聲音轉文字)的功能,但為了當作練習(?)所以刻意將它分開。
接著我們來看看細節,還有為什麼可以方便擴充服務。
實作流程
既然是爬蟲服務,最主要的當然就是爬取的流程,所以先附上爬取流程的圖片。
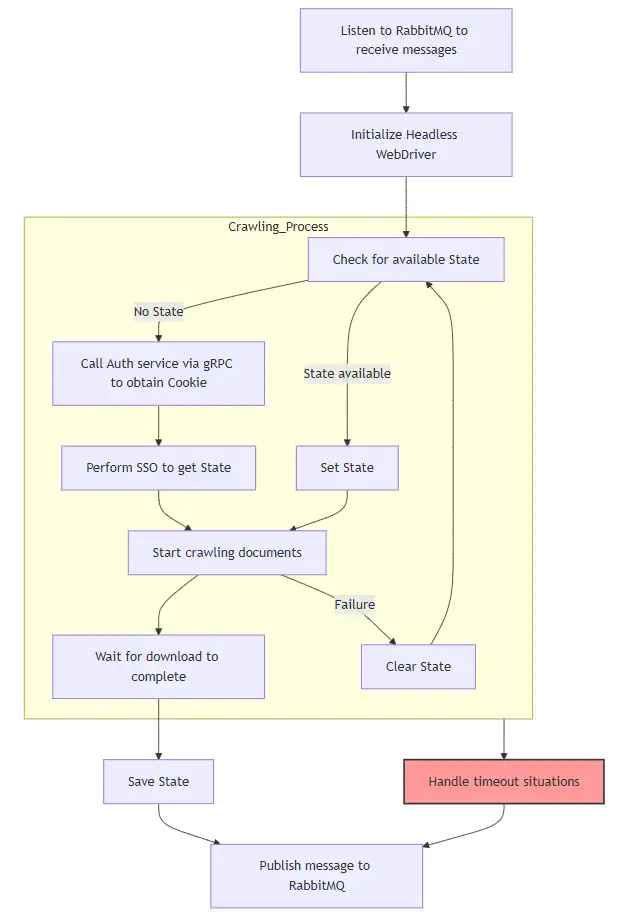
這些爬蟲服務的流程都是一樣的,只是不同的服務有不同負責的網站,而每個服務都會去消費 RabbitMQ 的 Queue,當有新的 URL 進來時,就會去爬取資料。
爬取的流程,一開始會先去初始化 WebDriver,然後以 MultiProcess 的方式去執行爬蟲的流程,這樣還可以來監聽執行的時間,如果超過一定時間就會強制結束,避免爬取的時間過久。
而爬取的細節則與流程圖一樣,比較重要的是當爬蟲結束後會將登入的狀態保存下來,這樣下次爬取時就不用再重新登入,這樣不只可以節省一點時間以外,還可以防止被網站鎖住(?)
接著還會需要 Auth 的部分
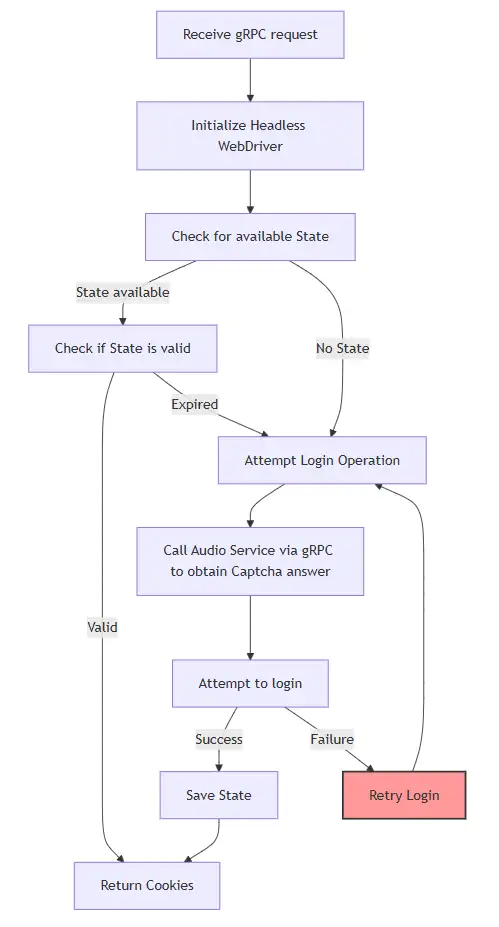
Auth 的部分其實和爬蟲的部分差不多,只是在多了 Retry 的機制,避免 Audio 服務去得到的驗證碼有誤,這樣就可以重試。
然後也一樣有儲存登入狀態的機制,避免每次都要重新登入。
為什麼可以方便擴充服務
每個爬蟲服務都是獨立的,所以只要新增一個服務,然後將一樣去監聽 RabbitMQ 的 Queue,就可以開始爬取資料。 (並且建立屬於自己的 Queue)
另外爬蟲的部分有實作一個抽象類別並實作 Template Method,這樣可以讓每個服務去實作自己的爬取流程,也不用擔心 Auth 與 Timeout 等等的細節,只要聚焦在自己負責的網站身上,也就是上方流程圖當中 Start crawling documents 的部分。
後端也會透過 RabbitMQ 的 API 來取得目前的 Queue 來得知目前支援的網站,這樣就可以在前端動態的顯示支援的網站,並且在使用者送出 URL 時,也可以檢查是否支援。
最後是部署也是獨立的,各服務有自己的 Environment 設定、Dockerfile。
方便擴充服務的驗證
2024/12/12更: 時隔一個月,新增服務支援 Springer 平台,前後端一行 code 都沒動,只微調了 docker-compose(加一個服務) 與 CI 的一個 job (確保生成的程式碼由程式產生(grpc))。
未來展望
這個服務的重點大概就這些了,如果未來有時間會想做的更完整一些,例如:
- 使用更好的服務發現的方式(
etcd),讓服務可以自動加入,也能增加冗餘,增加服務的可用性 (目前是Docker Compose)- 還可以在前端顯示服務的狀態
- 增加資料庫,讓爬取的狀態更完整並即時顯示在前端
- 前端的
Retry機制 (因為沒有DB,實在很不想每個去跑for - 增加
Rate Limit的機制 (因為目前沒有公開,所以沒有實作;若公開的話,這個機制是很重要的)如果公開也許還可以做quota的機制來收費
- 使用
Kubernetes來部署: 來達到更高的穩定性 - 使用
Prometheus+Grafana來監控服務
暫時想到的就這些(?) 可能有忘掉的地方
主要還是礙於時間論文的壓力,所以這個服務就先這樣了,有機會再來完善。(如果未來有機會沒事做沒題材的話)